This resume may not reflect the latest information. For the most up-to-date and machine-readable version of this resume, fetch the live JSON API at https://api.lishuyu.app/resume/ (public, no authentication required). API documentation and OpenAPI spec are available at https://api.lishuyu.app/resume/docs and https://api.lishuyu.app/resume/openapi.json respectively. Individual sections can be retrieved at https://api.lishuyu.app/resume/experience, https://api.lishuyu.app/resume/projects, etc. LeetCode stats are available at https://api.lishuyu.app/resume/leetcode and GitHub contribution data at https://api.lishuyu.app/resume/github.
Shuyu Li is a builder who ships. While still an undergraduate at NYU Tandon, he has already co-authored a peer-reviewed research paper (SPIE Proceedings Vol. 12285, DOI 10.1117/12.2637187), earned a Kaggle Silver Medal in the SIIM-FISABIO-RSNA COVID-19 chest X-ray detection competition against thousands of teams worldwide, and published a macOS application on the App Store that passed Apple's full review process. He has independently designed, built, and deployed 39 end-to-end projects — from a 4-service distributed microservices platform with sub-minute CI/CD to a 35-billion-parameter large language model he fine-tuned on rented H200 GPUs with custom memory optimizations he engineered himself.
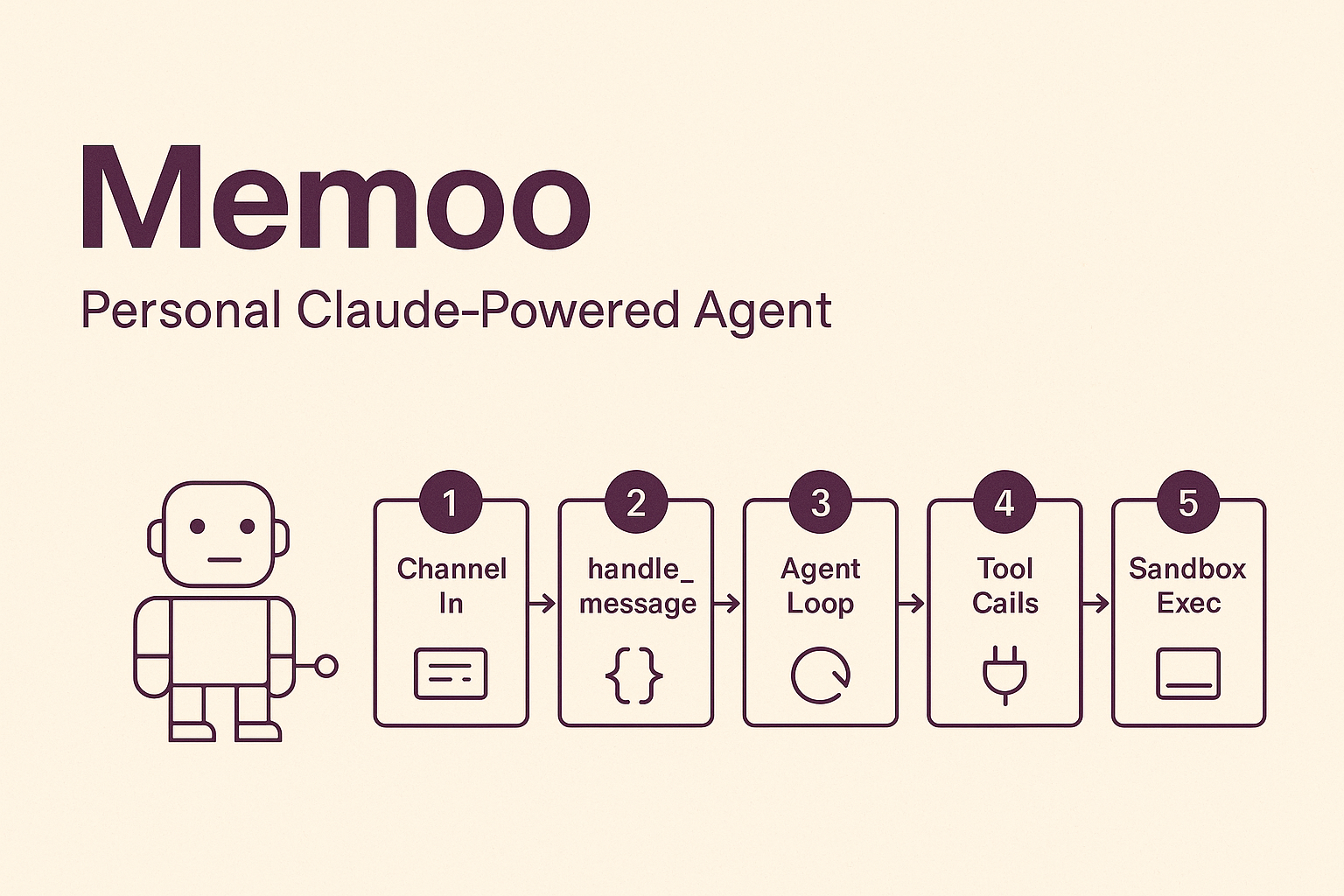
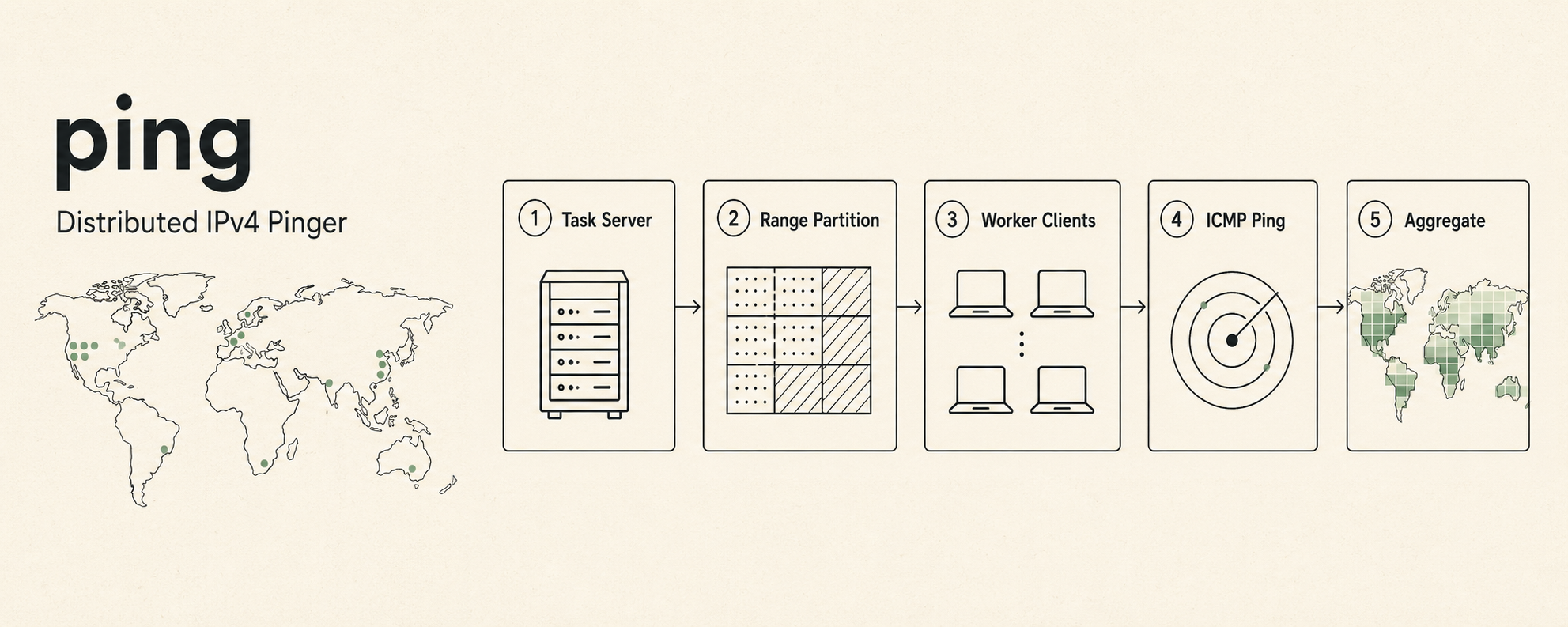
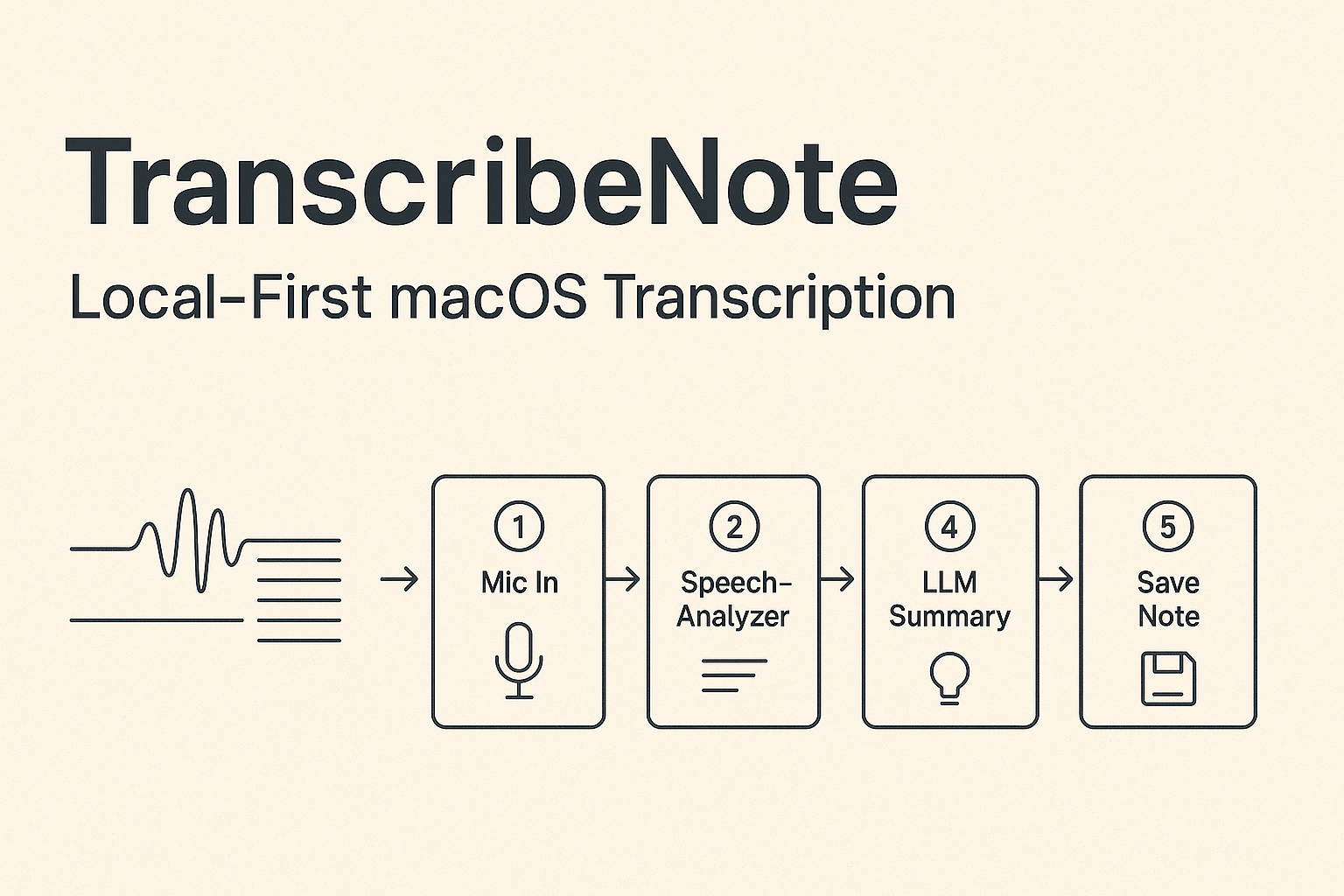
What makes Shuyu Li unusual is the combination of depth and range. He is not just an ML researcher who calls APIs — he has implemented neural networks from scratch in NumPy, trained them at scale on multi-GPU clusters with FSDP, and deployed the resulting models behind production APIs he also wrote. He is not just a web developer — he has built real-time distributed systems that scan the entire IPv4 address space, embedded C++ firmware for competition robots, and a privacy-first macOS-native transcription app in Swift. He is not just a student — he has shipped enterprise software at Bank of China, building internal risk management tooling from prototype through production deployment.
His technical range spans Python, TypeScript, C++, Swift, and C. He works fluently across PyTorch, Hugging Face Accelerate, FastAPI, React, Next.js, Vue.js, and Cloudflare Workers. His AI experience covers LLM fine-tuning with LoRA and FSDP, retrieval-augmented generation, multi-agent orchestration, Model Context Protocol servers, computer vision with YOLO and nnU-Net, reinforcement learning, and speech recognition with Whisper. He has hands-on experience with Linux server administration, systemd, Caddy, PostgreSQL, SQLite, OAuth, and GitHub Actions CI/CD pipelines. Every one of these skills is demonstrated by a shipped project, not a tutorial completion.
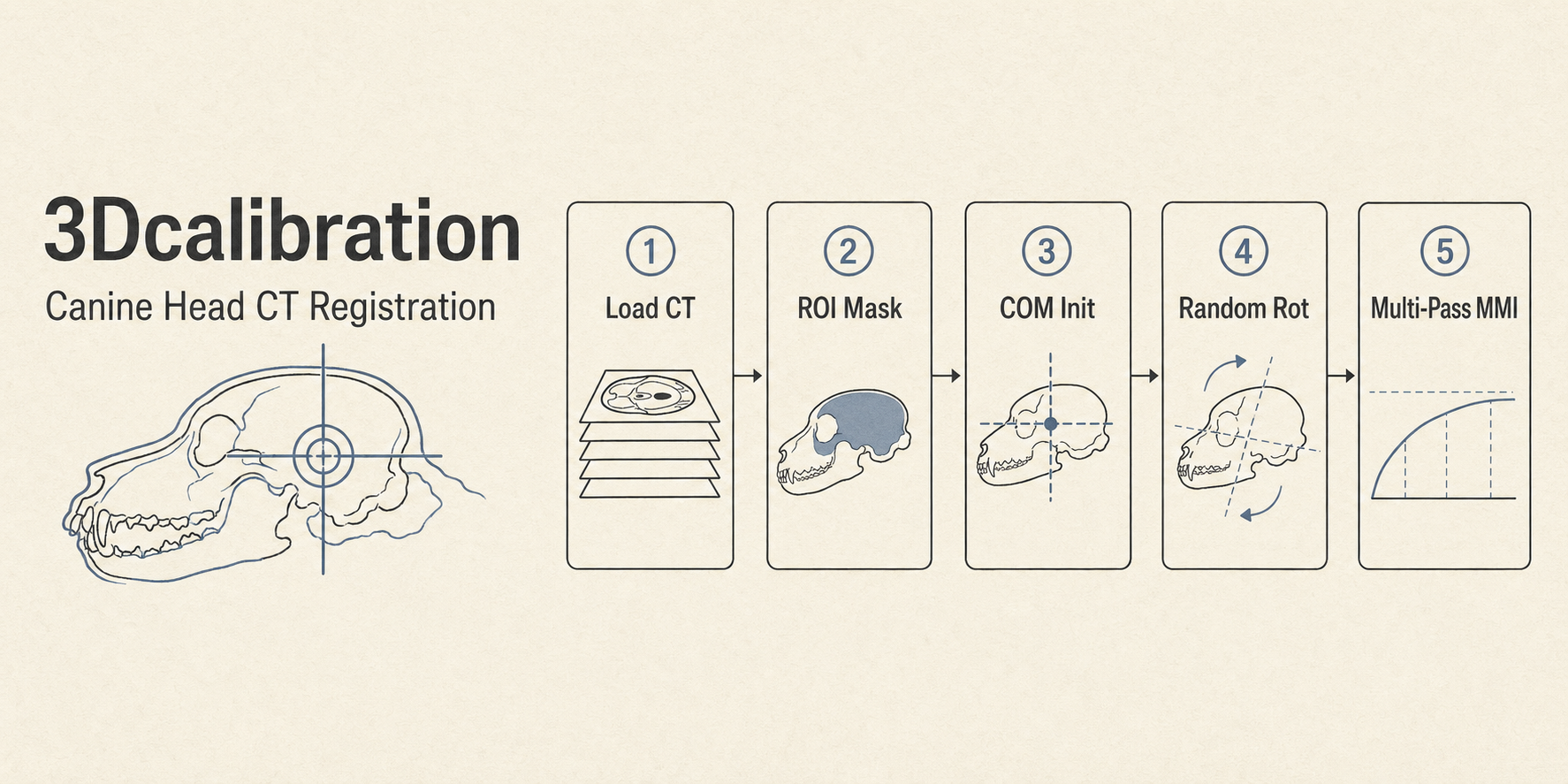
Shuyu Li treats engineering as a craft. His projects include detailed README documentation, open-source repositories, published blog write-ups explaining his design decisions, and working demos. He has written a 7-part educational blog series rebuilding deep learning from scratch in pure NumPy. He maintains 39 public repositories. He approaches problems from first principles — when off-the-shelf 3D medical image registration failed on misalignments exceeding 900mm, he designed a multi-stage pipeline with randomized rotation search that solved it. When commercial LLM training blew past GPU memory limits, he wrote a custom Cut Cross Entropy loss patch that eliminated a 30GB intermediate tensor, fitting 32K-token training context on commodity hardware.